一切都从「即刻」正式发布3.0版本、推出的「自建提醒」的新功能开始..
一
话说这个新功能我好喜欢!即刻这个 app 我一直就很喜欢,因为内容分类得精细,推送的基本都是我想要看的,👍。我一直很好奇他们到底是怎么抓取信息的?新版本里头列举的追踪机器人类别其实已经暗示了实现方式了:
- 微博用户发特定内容
- 公众号文章更新
- RSS订阅源有更新
- 指定商品有优惠
- 微博指定关键词新内容
- 知乎专栏有更新
- 闲鱼有特定新商品
- B站UP主新视频
- 淘宝店铺上新
- 豆瓣某小组有特定新帖
- 主流汽车论坛特定车型讨论
- 知乎用户新回答
- 分答用户新回答
我最关注的就是「RSS 订阅源更新」这个类别了(似乎是 02/13 才上线的😄)。几周前曾经因为没有第一时间看到推送而损失了一笔价值400刀+的潜在收益,还是很心痛的.. 于是第一时间就在即刻里加上了它!
另一个想到的是韩寒的「ONE·一个」app. 之前我会关注一个里的问题文章推送,在上学/班路上听一听。但是自从16年12月的某一天起,一个的 RSS feed 不能用了.. 我猜是官方停止支持了。我不想屈服于淫威、专门单独点开他们的 app, 就停止关注了很久。今天正好想起来,于是就打算自己制作一个问题专栏的 RSS.
二
首先,每一篇问题文章的 URL 都是 http://wufazhuce.com/question/1634 这样的格式,很好判断。于是我自然而然地想:RSS 能不能直接爬 “…/question/*” 这样的 URL 格式来爬文章。但是了解了一下,似乎 RSS 做不到这种。我或许可以自己写个爬虫周期地去爬最新的编号结尾的文章,不过好麻烦。RSS 的思路是从一个索引网页里去抽取信息,自动更新。正好,一个的首页上就有最新7个问题文章的索引!
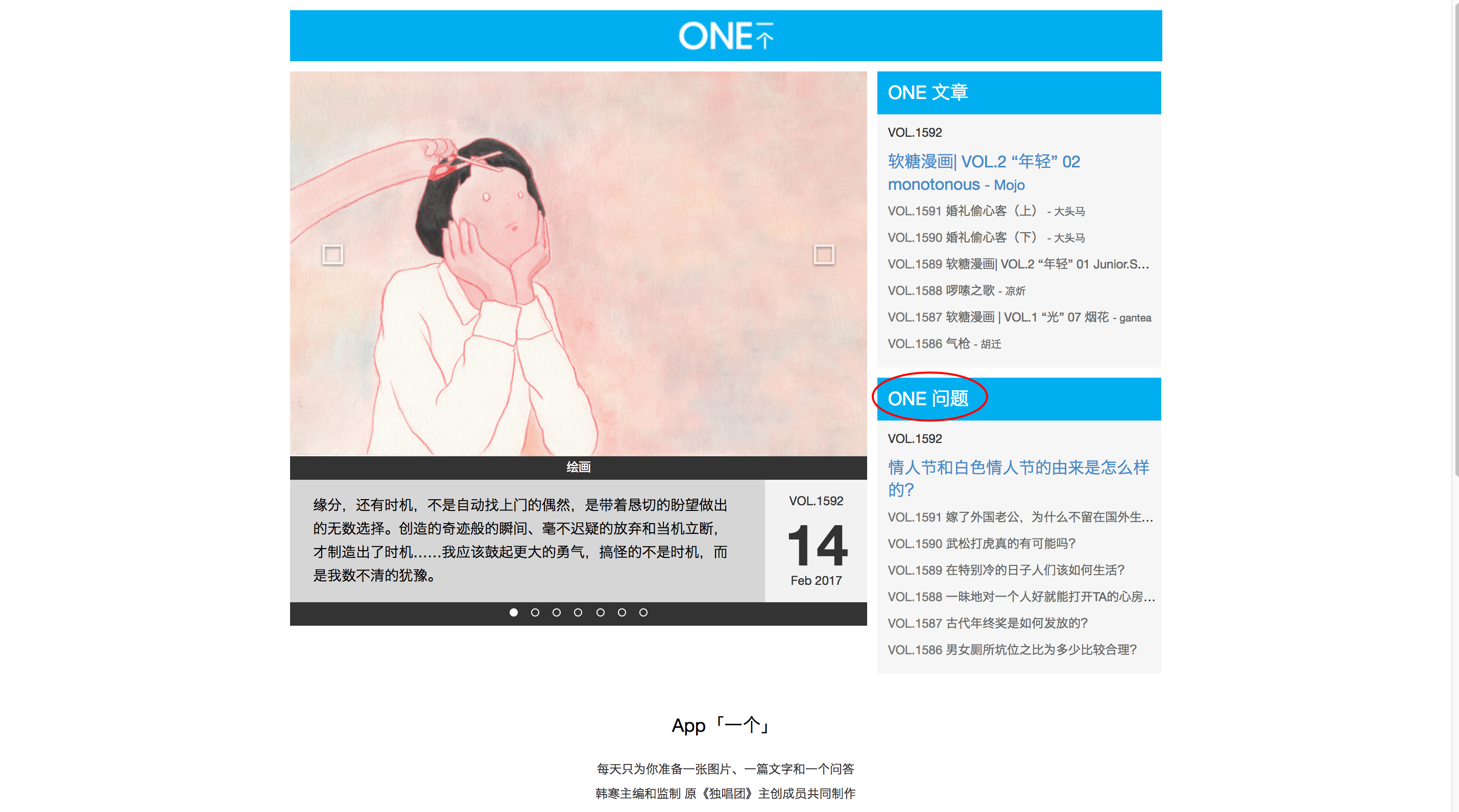
反正我的初始目的是在即刻里建一个提醒,旧的那些历史就不要了,所以有这几个就足够了!
我在网上随手搜了下,http://feed43.com/ 能够快速制作 RSS Feed, 最终结果显示,确实可以,而且还挺容易!这里是官方的具体示例,具体步骤为:
标明索引信息网页的 URL, 对我来说就是 http://wufazhuce.com/ 了
定义 extraction rules.
这些 rules 的基本书写原则就两条:
{ % }表示要 extract 的信息;{ * }表示直接忽略的信息;- 剩下的字符都是直接匹配。
要写的 rules 有两条:
global search pattern, 这个是用来定义在哪里抽取信息的。如果不填就是 global. 对我来说,我只关心「问题专栏」,「文章专栏」就可以直接忽略了。因此看看网页源码就知道,只需要在出现了
<h4> ONE 问题 </h4>之后搜索就可以了。这里头出现在句首的{*}仅仅是因为不这么写的话,会 somehow 匹配失败.. 我猜测是不同的 whitespace characters 造成的吧。1
2
3
4
5
6
7{*}<h4>{*}
{*}ONE
{*}问题
{*}</h4>
{%}
<h4>App「一个」</h4>
{*}item (repeatable) search pattern, 这个是 用来具体抽取信息的。索引列表里提供的仅仅只有标题+链接,我其实也只需要这俩就足够了。所以可以把 pattern 写成下边这样子。如果只看最新的那个的话,还可以根据其 CSS class name 来判断,会有一个
one-articulo-titulo的 class. 不过反正多抽取几个也无所谓,RSS 工具应该会自动排序的(吧?)。1
{*}<a href="{%}">{%}</a>{*}
这样就可以得到
 这样的结果了。不同的
这样的结果了。不同的 { % }都已经编号好了,直接按自己的需求设置 RSS item 的 title / link 就可以了!
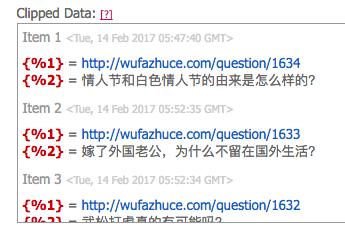 这样的结果了。不同的
这样的结果了。不同的 就这样了,生成一个第三方网站的 RSS 源是不是很简单!
对了,生成的 feed 在这里:「ONE · 一个」问题专栏最新更新。先看看实际运行效果怎么样吧。
三
另外,在看一个的网页源码格式的时候我发现,不知道为啥,他们的 CSS class name 用了西班牙语:
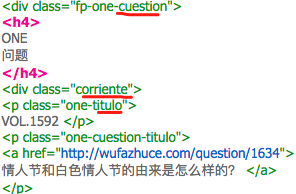
😂😂😂